High-Performance Computing Center Stuttgart

“To the best of our knowledge, this is the largest simulation ever done on European HPC infrastructure,” says Dr. Theresa Pollinger, who recently completed her PhD at the University of Stuttgart Department Institute for Parallel and Distributed Systems (IPVS) and led the experiment. She will present a paper on the project at the upcoming SC24 conference, a meeting of the international high-performance computing community that takes place in Atlanta, Georgia, on November 17-22, 2024.
Explaining the significance of the experiment, Pollinger says, “The ability to combine the three supercomputers of the Gauss Centre for Supercomputing suggests that with enough bandwidth for data transfer and the ability to coordinate resource availability, it could be possible to use a federated system of supercomputers to run large-scale simulations for which a single system cannot offer enough memory.”
In conducting their experiment, Pollinger and her colleagues simulated a system inspired by a problem in plasma physics that is relevant for studying nuclear fusion. In the future, fusion could offer an abundant, carbon-free source of energy and so physicists and engineers have been investigating the processes involved using high-performance simulations. Because of the massive computing resources that are required to simulate such complexity, however, the calculations must typically make compromises in the resolution they can offer.
Simulating fusion in high fidelity involves mathematical models called the Vlasov equations. Here, the space containing the reaction is computationally subdivided into a grid of small virtual boxes. Within each box, an algorithm simulates changes over very short timesteps in six dimensions — 3 spatial dimensions plus 3 velocity dimensions. This approach can simulate fusion reactions at extremely high resolution. The problem, however, is that it also quickly generates enormous amounts of data, overwhelming available data storage resources and wasting valuable computing time because of data transfer needs. Computational scientists call this the “curse of dimensionality.”
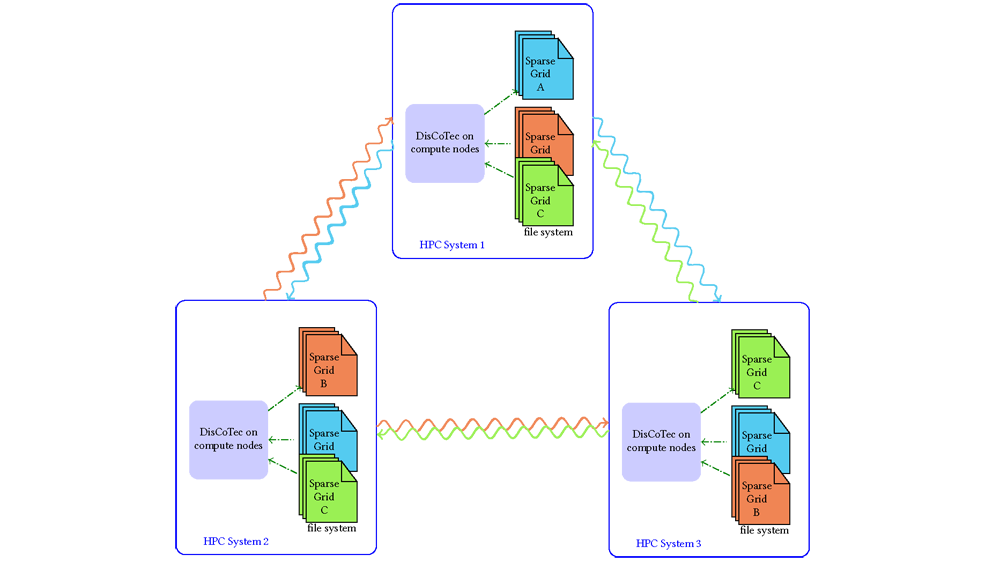
Pollinger and her IPVS colleagues have been exploring how a multiscale computing approach called the sparse grid combination technique could address this problem. Instead of simulating each of the small boxes at high resolution, they fuse groups of small boxes together to form larger boxes, reducing the resolution. They repeat this approach multiple times, combining each box with different groups of its neighbors. The results of these lower resolution simulations are then combined to produce an overall result. As Pollinger explains, “All of the boxes are resolved badly, but are bad in different ways. By summing them up in a clever way, we get a good approximation that is finely resolved in all directions.”
Although supercomputers have been combined to perform large simulations in the past, this has typically involved running different components of a larger algorithm on systems that are best suited to them. In the Pollinger team’s experiment, however, large numbers of similar operations were executed on all three GCS machines in parallel.
The team implemented the sparse grid combination technique using a programming framework called DisCoTec. This approach distributed the computational workload by simultaneously running multiple variants of the simulation on different supercomputers (i.e., different low-resolution groupings of boxes in the computational mesh), while also following the same timesteps. This has the important advantage that simulations at the three HPC centers are loosely coupled, taking place largely independently of one another during major segments of the algorithm’s overall runtime. Data exchange among them was required only occasionally, removing time consuming communication steps. Moreover, it was not necessary to transfer large datasets containing the comprehensive results of all calculations. The multiscale nature of the combination technique means that only specific chunks of comparatively coarse data need to be shared and combined to provide the highly resolved final result. This dramatically simplifies memory requirements and makes it much easier to transfer data over the Internet.
In addition to brute computing power, the experiment relied on the high-speed, 100 Gbit per second research network that connects supercomputers at the three GCS centers, and on the UFTP data transfer software from the Forschungszentrum Jülich. This infrastructure was set up in 2017 under the auspices of the InHPC-DE project, supported with funding from the German Ministry of Education and Research (BMBF). “The tool already existed at GCS, but it was designed to enable users to make data backups or to move data between different systems for different processing steps,” Pollinger explains. “What is new is that we used this system in a highly parallelized manner as an integral part of our production environment.”
In an initial test in September 2023, the researchers used SuperMUC-NG and JEWELS to run a simulation including 46 trillion degrees of freedom, a size that would overwhelm the memory capabilities of SuperMUC-NG when running alone. They followed this up in November 2023 in an experiment that simultaneously used approximately 20% of compute nodes on each of the three GCS systems — JUWELS, SuperMUC-NG, and Hawk. Using conventional approaches on a single supercomputer, the data requirements of such a high-dimensional simulation would have made it impossible to calculate. Using the sparse grid combination technique on the GCS superfacility, however, Pollinger and her team were able to complete this massive job.
Combining three of Europe’s largest supercomputers in this way posed a variety of challenges. The first was organizational. During normal operation, each system executes multiple computing jobs from several users simultaneously. These jobs are coordinated using independent queueing systems at each HPC center. During tests and in the final run of the plasma physics simulations, however, it was important for Pollinger and her team to reserve large amounts of computing capacity simultaneously on all three machines.
In addition, network bandwidth on supercomputers like those in Jülich, Garching, and Stuttgart is optimized to enable users to transfer files between the HPC centers and their local computing infrastructures. In this case, nearly all of the available bandwidth was consumed by a single experiment. This also required planning between the research team and system administrators at the three centers. In the future, a unified queuing system that could automatically distribute a simulation across a federated HPC superfacility would make this approach more practical.
Staff at Hewlett Packard Enterprise (HPE), manufacturers of HLRS’s Hawk supercomputer, also made important contributions to the experiment. HPE scientist Philipp Offenhäuser analyzed input/output performance on Hawk’s Lustre file management system to identify bottlenecks. This included optimizing how files were written in advance to suit the I/O pattern utilized in this unusual application. Improving system performance also involved selecting domain decompositions to address potential load imbalances, and exploring compression techniques to further reduce the need for data transmission across the network.
As demand for compute, memory, and storage capacity in extreme-scale, grid-based simulations grows, this test case demonstrated a strategy for running them at a much higher resolution than would otherwise be possible.
— Christopher Williams
Pollinger T, Van Craen A, Offenhäuser P, Pflüger D. 2024. Realizing joint extreme-scale simulations on multiple supercomputers—two superfacility case studies. In 2024 SC24: International Conference for High Performance Computing, Networking, Storage and Analysis SC, Atlanta, GA, United States. 1568-1584.
Funding for Hawk, JUWELS and SuperMUC-NG is provided by the German Federal Ministry of Education and Research through the Gauss Centre for Supercomputing (GCS). Additionally, Hawk is supported by the Baden-Württemberg Ministry for Science, Research, and the Arts, JUWELS by the Ministry of Culture and Science of the State of North Rhine-Westfalia, and SuperMUC-NG by the Bavarian State Ministry of Science and Arts.
A member of the Gauss Centre for Supercomputing, HLRS is one of three German national centers for high-performance computing.